
Temperature in Colombia: Understanding Factors & Predictive Model Proposal
Authors: Ana Cruz, Andrés Riaño, Gabriela Rincón, Oscar Rosero, and Elsa Quicazán
Explore the code on Github
Overview
Climate change is affecting Colombia and requires a deeper understanding of its temperature patterns and the factors that influence it. EcoTemp emerged as a tool to understanding climate change in Colombia by collecting information from main national and international entities such as the World Bank, FAO, IDEAM, and DANE.
- It provides three scenarios for predicting the average national temperature,
- It describes the annual behavior of temperature-affecting factors, and
- It presents interactive graphs of temperature, deforestation, and GDP historical data at the departmental level.
Our team utilized our expertise in mathematics, economics, engineering, biology, and our Data Science training from DS4A to work together.
Main findings

The change in temperature, which is an indicator of climate change, was almost 1°C in Colombia between 1990 and 2019.

The Gross Domestic Product (GDP), referred to as PIB in Spanish, is a variable that displayed an upward trend over time, mirroring the pattern of temperature increase.

The urban population increased from 69% in 1990 to 81% in 2019, far exceeding the global estimate of 68% of the urban population by 2050.

The number of cattle heads is similar in pattern to the production of methane by agriculture.

Forest cover decreased from 57% in 1990 to 52% in 2019. The department with the highest deforestation over the years is Caquetá, located in the Amazon region.

The Gross Domestic Product (GDP) is concentrated in regions other than those with the highest deforestation, meaning that the exploitation of natural wealth is not reflected in the improvement of the local economy.
Model findings:
Three possible scenarios for the temperature in 2040 and its increase relative to the 1990-2000 period are:
- If we keep doing business as usual, so that energy consumption, gas emissions, GDP, population growth, and deforestation continue at their current rate, we will reach 25°C, which is an increase of 1.58°C.

- If energy consumption, gas emissions, GDP, population growth, and deforestation decrease, we will reach 24.5°C, an increase of 1.13°C.

- If energy consumption, gas emissions, GDP, population growth, and deforestation increase considerably (7% per year each), we will reach 27°C, an increase of 4°C.

Exploring Economic, Social, and Political events impacting data tendencies
The tendencies found in our data offer insights into the factors influencing temperature rise. However, investigating correlations with other factors, such as significant economic, social, and political events, was beyond the scope of our study. Understanding the impact of these events on data tendencies provides a comprehensive understanding of analyzed trends.
Some of the relevant events that occurred in Colombia during the years under study include:
- 1999: Economic crisis
- 2011: El Niño phenomenon
- 2014: Promotion Law 1715 which eliminated import tariffs for solar panels
- 2015: Colombia’s membership in the International Renewable Energy Agency (IRENA)
- 2016: Peace Agreement signing
- 2018: Emergency at the hydroelectric Hidroituango
- 1985 – 2020: Forced displacements per year in Colombia. Figure from the online newspaper “La Silla Vacía“

Technical Information
The case diagram (fig 1) shows the relationships between actors and use cases within our system.

The dashboard was created using Dash, HTML, CSS, Bootstrap and the Plotly library. It included line plots, bar plots, choropleth maps, and interactive line plots with sliders. The model predicted temperature based on factors including forest area, energy consumption, population, greenhouse gas emissions, and GDP. The dataset was obtained from sources such as IDEAM, Our World in Data, and the World Bank database. The project was implemented using Python libraries such as Matplotlib, Seaborn, Bokeh, Plotly, Pandas, Numpy, Scikit-learn, Tensorflow, and Statsmodels. Our app coding and datasets are located in the GitHub repository https://github.com/Osc2405/DS4A_team38
Data analysis and computation
The goal of the study was to predict temperature in Colombia. We performed Exploratory Data Analysis (EDA) and observed the relationships between temperature and other variables such as population, forest area, energy consumption, greenhouse gas emissions, and GDP. Some of them are already mentioned in the main findings, and here we present the remaining ones:

Rise and subsequent decline of the rural population over time

There has been an overall increase in energy consumption, with oil consumption being the primary contributor. However, it is important to note that gas consumption has experienced the most rapid growth.

Until around 2008, the majority of renewable energy consumption in Colombia was derived from hydropower. However, other renewable energy sources started gaining traction during that time.

There has been a notable increase in emissions, with CO2 being the primary contributor and the fastest-growing source.

In the Main findings section, we have already highlighted the close relationship between methane production and cattle heads. Here, we further demonstrate that methane emissions align with the overall trend of agricultural methane emissions. Similarly, we observe that nitrous oxide emissions in agriculture follow the same pattern as agricultural nitrous oxide emissions.
Models
For the model, we chose relevant variables based on the interaction between temperature and independent variables and among the independent variables themselves, including forest area, fossil fuel consumption, renewables consumption, total population, total greenhouse gasses emissions, and GDP. Existing models like EN-ROADS predict global temperature and greenhouse gas emissions using data from social, economic, law enforcement, and production sources, but our aim was to create a model specifically focused on Colombia.
The study used a train-test dataset with the train data covering 1990-2015 and the test data from 2016-2020. The majority (86%) of the data was used for training and 4 entries for testing. Initially, an OLS model was used, but due to multicollinearity among predictors, the results were unreliable.
Chosen model: Bayesian Ridge Regression Model
The final model used was a Bayesian model (fig 3), which provides more accurate and robust results due to its ability to handle uncertainty and incorporate prior knowledge. The Bayesian model was implemented using the PyMC3 library in Python and was able to predict temperature in Colombia with a high degree of accuracy. We presented the results of the Bayesian model in the final application, providing valuable insights into the behavior of temperature in Colombia and its relationship with other environmental, economic, and social factors.

| Metric | Result |
| RMSE | 0.1306 |
| MAE | 0.1116 |
Fig 3. Bayesian Ridge Regression Model ResultsWeb application
The dashboard was developed using Dash, HTML, CSS, Bootstrap and Plotly library and showcases a variety of visualizations such as line plots, bar plots, choropleth maps, and interactive line plots with sliders. It provides an overview of the EcoTemp project’s motivation and key data in the “Home” section (fig 4), a prediction of temperature change at the national level in the “Prediction” section (fig 5), and a visualization of temperature-related variables at the departmental (figs 6, 7) and national level (fig8) in the “Description” section, including heat maps, indicators for the selected year, and a slider to compare trends in variables such as energy consumption and greenhouse gas emissions. The “About Us” section (fig 9) presents information about the project team and includes their logo, symbolizing the impact of climate change, personal information, and social media links.



Fig 4. EcoTemp Home Section providing a brief overview of the project's motivation and presenting key data obtained from the information analysis.





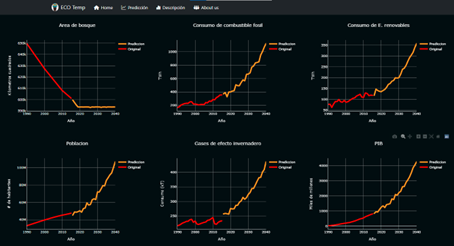
Fig 5. EcoTemp Prediction Section showing the model's forecast of temperature at the national level with the best, medium, and worst options for future temperature change. The figure also displays the changes in variables such as forest area, fuel consumption, renewable energy consumption, population, greenhouse gases, and GDP in the 3 proposed scenarios.

Fig 6. EcoTemp Description Section displaying the visualization of variables related to temperature change at the national and departmental level. The section includes a heat map showcasing the data of temperature, PIB, and deforestation. The map is created using a geojson map of Colombia divided by department with a code assigned to each department. The forest data is extracted from a panda series and is presented in each area using the department ID

Fig 7. EcoTemp Description Section featuring a section with indicators for the last year in the selected range.



Fig 8. EcoTemp Description Section showcasing the use of a slider to change the year in the maps and compare trends in variables such as energy consumption, greenhouse gas emissions, population, and land uses. The section also presents a line diagram contrasting variables such as cattle vs. gas emissions, population vs. GDP, and GDP vs. CO2 emissions, showing a positive correlation in both trends.


Fig 9. EcoTemp About Us Section presenting information on the project team and its origin. The section includes the team's logo, symbolizing the impact of climate change on Colombian paramos, a source of life. The team is represented by a frailejon icon. Personal information, such as LinkedIn contacts and other social media links, are also displayed.
Deployment
The solution was deployed on a virtual machine using GCP, and later on Google Cloud Platform and Heroku’s serverless services. The Serverless application deployed in Cloud Run has 2GB memory, 4 CPUs, a 300 sec request timeout, and a maximum of 10 instances.
Conclusion
The study provided an understanding of temperature behavior in Colombia and the factors that influence it. The predictive model and interactive dashboard offered valuable insights and information for informed decision making. The deployment in serverless services on Google Cloud Platform offers scalability and accessibility to users.
Acknowledgements
This was the final project for the Data Science for All Certification. We would like to express our gratitude to the Ministerio de Tecnologías de la Información y Comunicaciones for providing us with this opportunity and to all the individuals who offered their advice and expertise. Special thanks to our TAs, Aura Forero and David Alfredo Quintero Olaya, and the Data Science for All by Correlation One under the leadership of Oscar Adolfo Pérez Tuta for their invaluable contributions. We also acknowledge the valuable insights from Luis Enrique Carreño Herreño.
Software: Python (pandas, numpy, scipy, sklearn, statsmodels, plotly, ipywidgets, cufflinks, matplotlib, seaborn), Dash, HTML, CSS.
Difficulty: Difficult
Databases:
- View our project and its datasets at https://github.com/Osc2405/DS4A_team38/
Category: Modeling, visualization